
Reducción de los tiempos de cómputo de la Migración Sísmica usando FPGAs y GPGPUs: Un artículo de revisión
Main Article Content
Keywords
Evaluación del desempeño, FPGA, GPGPU, Métodos sísmicos de exploración, Migración Sísmica.
Resumen
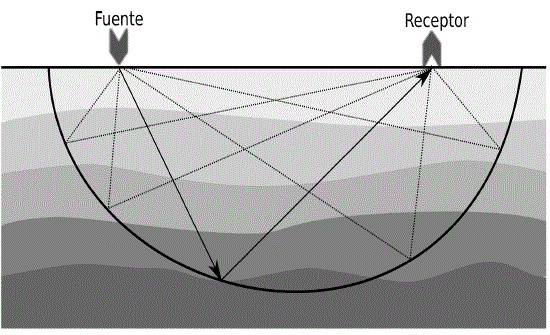
Este artículo hace una revisión entorno a los esfuerzos que actualmente se están realizando con el propósito de reducir el tiempo de cómputo de la MS. Nosotros introducimos los métodos más utilizados para realizar el proceso de Migración, así como también las dos arquitecturas computacionales que están ofreciendo mejores tiempos de procesamiento. Revisamos las implementaciones más representativas de este proceso sobre estas dos tecnologías y resumimos los aportes de cada una de estas investigaciones. El artículo finaliza con un análisis acerca de la dirección que deben tomar futuras investigaciones en esta área.
PACS: 93.85.Rt
MSC: 68M20
Descargas
Referencias
[2] A. Brodtkorb, “Scientific Computing on Heterogeneous Architectures,” Ph.D. dissertation, University of Oslo, 2010. [Online]. Available: http://babrodtk.at.ifi.uio.no/files/publications/brodtkorb_phd_thesis.pdf 263, 275, 276
[3] R. G. Clapp, H. Fu, and O. Lindtjorn, “Selecting the right hardware for reverse time migration,” The Leading Edge, vol. 29, no. 1, p. 48, 2010. [Online]. Available: http://link.aip.org/link/LEEDFF/v29/i1/p48/s1&Agg=doi 263, 273, 275, 276
[4] J. Cabezas, M. Araya-Polo, I. Gelado, N. Navarro, E. Morancho, and J. M. Cela, “High-Performance Reverse Time Migration on GPU,” 2009 International Conference of the Chilean Computer Science Society, pp. 77–86, 2009. 263, 268
[5] R. Abdelkhalek, H. Calandra, O. Coulaud, J. Roman, and G. Latu, “Fast seismic modeling and Reverse Time Migration on a GPU cluster,” 2009 International Conference on High Performance Computing & Simulation, pp. 36–43, 2009. 263, 268
[6] V. K. Madisetti and D. G. Messerschmitt, “Seismic migration algorithms using the FFT approach on the NCUBE multiprocessor,” ICASSP-88., International Conference on Acoustics, Speech, and Signal Processing, pp. 894–897, 1988. 264
[7] S. Yerneni, S. Phadke, D. Bhardwaj, S. Chakraborty, and R. Rastogi, “Imaging subsurface geology with seismic migration on a computing cluster,” Current Science, vol. 88, no. 3, pp. 468–478, 2005. 264, 265, 266, 267
[8] V. K. Madisetti and D. G. Messerschmitt, “Seismic migration algorithms on parallel computers,” IEEE Transactions on Signal Processing, vol. 39, no. 7, pp. 1642–1654, 1991. 265
[9] J. F. Claerbout, “Basic Earth Imaging,” p. 220, 2010. [Online]. Available: http://sepwww.stanford.edu/sep/prof/bei11.2010.pdf.2011.pdf 266, 267
[10] S. H. Gray, J. Etgen, J. Dellinger, and D. Whitmore, “Seismic migration problems and solutions,” Geophysics, vol. 66, no. 5, p. 1622, 2001. 266, 267
[11] C. He, M. Lu, and C. Sun, “Accelerating Seismic Migration Using FPGA-Based Coprocessor Platform,” 12th Annual IEEE Symposium on Field-Programmable Custom Computing Machines, pp. 207–216, 2004. 267, 277, 279
[12] D. Brandao, M. Zamith, E. Clua, A. Montenegro, A. Bulcao, D. Madeira, M. Kischinhevsky, and R. C. P. Leal-Toledo, “Performance Evaluation of Optimized Implementations of Finite Difference Method for Wave Propagation Problems on GPU Architecture,” 2010 22nd International Symposium on Computer Architecture and High Performance Computing Workshops, pp. 7–12, 2010. 268, 277
[13] E. Baysal, “Reverse time migration,” Geophysics, vol. 48, pp. 1514–1524, 1983. 268
[14] M. Araya-polo, J. Cabezas, M. Hanzich, M. Pericas, I. Gelado, M. Shafiq, E. Morancho, N. Navarro, M. Valero, and E. Ayguade, “Assessing Accelerator-Based HPC Reverse Time Migration,” Electronic Design, vol. 22, no. 1, pp. 147–162,
2011. 268, 270, 271, 276, 284
[15] P. Farmer, S. Gray, G. Hodgkiss, A. Pieprzak, and D. Ratcliff, “Structural Imaging : Toward a Sharper Subsurface View,” Oilfield Review, vol. 1, no. 1, pp. 28–41, 1993. 268, 269, 270
[16] A. Albertin, J. Kapoor, R. Randall, and M. Smith, “La era de las imágenes en escala de profundidad,” Oilfield Review, vol. 14, no. 1, pp. 2–17, 2002. 268, 269
[17] S. Abreo and A. Ramirez, “Viabilidad de acelerar la migración sísmica 2D usando un procesador específico implementado sobre un FPGA The feasibility of speeding up 2D seismic migration using a specific processor on an FPGA,” Ingeniería e investigación e investigación, vol. 30, no. 1, pp. 64–70, 2010. 270, 273
[18] M. Flynn, R. Dimond, O. Mencer, and O. Pell, “Finding Speedup in Parallel Processors,” 2008 International Symposium on Parallel and Distributed Computing, pp. 3–7, 2008. 270
[19] Xilinx Inc., “Xilinx Intellectual Property.” [Online]. Available: http://www.xilinx.com/products/intellectual-property/ 272
[20] Altera Corporation, “Altera: Intellectual Property & Reference Designs.” [Online]. Available: http://www.altera.com/products/ip/ 272
[21] K. Compton and S. Hauck, “Reconfigurable computing: a survey of systems and software,” ACM Computing Surveys, vol. 34, no. 2, pp. 171–210, 2002. [Online]. Available: http://portal.acm.org/citation.cfm?doid=508352.508353 272
[22] I. Skliarova and V. Sklyrov, “Recursion in reconfigurable computing: A survey of implementation approaches,” Field Programmable Logic and Applications, 2009. FPL 2009. International Conference on, pp. 224–229, 2009. 272
[23] A. Gomperts, A. Ukil, and F. Zurfluh, “Development and Implementation of Parameterized FPGA-Based General Purpose Neural Networks for Online Applications,” Industrial Informatics, IEEE Transactions on, vol. 7, no. 1, pp. 78–89, 2011. 272
[24] Y. Lee and S.-B. Ko, “FPGA Implementation of a Face Detector using Neural Networks,” in Electrical and Computer Engineering, 2006. CCECE ’06. Canadian Conference on, May 2006, pp. 1914–1917. 272
[25] E. A. Zuraiqi, M. Joler, and C. G. Christodoulou, “Neural networks FPGA controller for reconfigurable antennas,” in Antennas and Propagation Society International Symposium (APSURSI), 2010 IEEE, 2010, pp. 1–4. 272
[26] V. Gupta, K. Khare, and R. P. Singh, “FPGA Design and Implementation Issues of Artificial Neural Network Based PID Controllers,” in Advances in Recent Technologies in Communication and Computing, 2009. ARTCom ’09. International Conference on, 2009, pp. 860–862. 272
[27] K. Puttegowda, W. Worek, N. Pappas, A. Dandapani, P. Athanas, and A. Dickerman, “A run-time reconfigurable system for gene-sequence searching,” in VLSI Design, 2003. Proceedings. 16th International Conference on, 2003, pp. 561–566. 272
[28] I. a. Bogdán, J. Rivers, R. J. Beynon, and D. Coca, “High-performance hardware implementation of a parallel database search engine for real-time peptide mass fingerprinting.” Bioinformatics (Oxford, England), vol. 24, no. 13, pp. 1498–1502, 2008. 272
[29] S. Baghel and R. Shaik, “FPGA implementation of Fast Block LMS adaptive filter using Distributed Arithmetic for high throughput,” in Communications and Signal Processing (ICCSP), 2011 International Conference on, 2011, pp. 443–447. 272
[30] M. Rawski, P. Tomaszewicz, H. Selvaraj, and T. Luba, “Efficient Implementation of digital filters with use of advanced synthesis methods targeted FPGA architectures,” in Digital System Design, 2005. Proceedings. 8th Euromicro Conference on, 2005, pp. 460–466. 272
[31] Y. Wang and Y. Shen, “Optimized FPGA Realization of Digital Matched Filter in Spread Spectrum Communication Systems,” Computer and Information Technology, IEEE 8th International Conference on, pp. 173–176, 2008. 272
[32] R. Tessier and W. Burleson, “Reconfigurable Computing for Digital Signal Processing A Survey,” Journal of VLSI Signal Processing, vol. 28, pp. 7–27, 2001. 272
[33] R. Sinnappan and S. Hazelhurst, “A Reconfigurable Approach to Packet Filtering,” in Field-Programmable Logic and Applications, ser. Lecture Notes in Computer Science, G. Brebner and R. Woods, Eds. Springer Berlin / Heidelberg,
2001, vol. 2147, pp. 638–642. 272
[34] Y. H. Cho and W. H. Mangione-Smith, “Deep network packet filter design for reconfigurable devices,” ACM Trans. Embed. Comput. Syst., vol. 7, no. 2, pp. 21–26, 2008. 272
[35] X. Tian and K. Benkrid, “Design and implementation of a high performance financial Monte-Carlo simulation engine on an FPGA supercomputer,” in ICECE Technology, 2008. FPT 2008. International Conference on, 2008, pp. 81–88. 272
[36] N. A. Woods and T. VanCourt, “FPGA acceleration of quasi-Monte Carlo in finance,” in Field Programmable Logic and Applications, 2008. FPL 2008. International Conference on, 2008, pp. 335–340. 272
[37] D. A. Hauck Scott, Reconfigurable computing. The theory and practice of FPGABASED computing. ELSEVIER - Morgan Kaufmann, 2008. 273
[38] H. Fu, W. Osborne, R. G. Clapp, O. Mencer, and W. Luk, “Accelerating seismic computations using customized number representations on FPGAs,” EURASIP J. Embedded Syst., vol. 2009, pp. 1–13, 2009. [Online]. Available:
http://dx.doi.org/10.1155/2009/382983 273
[39] A. J. Virginia, Y. D. Yankova, and K. L. M. Bertels, “An empirical comparison of ANSI-C to VHDL compilers : Spark, Roccc and DWARV,” in Anual Workshop on Circuits, Systems and Signal Processing (ProRISC),, Veldhoven,
Netherlands, 2007, pp. 388–394. 274
[40] Altera Corporation, “Implementing FPGA Design with the OpenCL Standard,” p. 9, 2012. [Online]. Available:
http://www.altera.com/literature/wp/wp-01173-opencl.pdf 274
[41] N. Dave, “A Unified Model for Hardware/Software Codesign,” Ph.D. dissertation, Massachusetts Institute Of Technology, 2011. 274
[42] R. Sánchez Fernández, “Compilación C a VHDL de códigos de bucles con reuso de datos,” Tesis, Universidad Politécnica de Cataluña, 2010. 274
[43] Y. Yankova, K. Bertels, S. Vassiliadis, R. Meeuws, and A. Virginia, “Automated HDL Generation: Comparative Evaluation,” 2007 IEEE International Symposium on Circuits and Systems, pp. 2750–2753, May 2007. 274
[44] P. I. Necsulescu, “Automatic Generation of Hardware for Custom Instructions,” Ph.D. dissertation, Ottawa, Canada, 2011. 274
[45] P. I. Necsulescu and V. Groza, “Automatic Generation of VHDL Hardware Code from Data Flow Graphs,” 6th IEEE International Symposium on Applied Computational Intelligence and Informatics, pp. 523–528, 2011. 274
[46] J. Bier and J. Eyre, “BDTI Study Certifies High-Level Synthesis Flows for DSPCentric FPGA Designs,” Xcell Journal Second, no. 71, pp. 12–17, 2010. 274
[47] NVIDIA Tesla, “GPU Computing revolutionizing High Performance Computing,” 2010. [Online]. Available:
http://www.nvidia.com/docs/IO/100133/tesla-brochure-12-lr.pdf 275, 276
[48] A. Brodtkorb, C. Dyken, T. R. Hagen, and J. M. Hjelmervik, “State-of-the-art in heterogeneous computing,” Scientific Programming, vol. 18, pp. 1–33, 2010. 275
[49] J. D. Owens, D. Luebke, N. Govindaraju, M. Harris, J. Krüger, A. E. Lefohn, and T. J. Purcell, “A Survey of General-Purpose Computation on Graphics Hardware,” Computer Graphics Forum, vol. 26, no. 1, pp. 80–113, 2007. 275, 276
[50] F. Warg, J. Nilsson, M. Ekman, and At An In-depth Look, “An In-Depth Look at Computer Performance Growth,” SIGARCH Comput. Archit. News, vol. 33, pp. 144–147, 2005. 276
[51] W. Lei, Z. Yunquan, Z. Xianyi, and L. Fangfang, “Accelerating Linpack Performance with Mixed Precision Algorithm on CPU+GPGPU Heterogeneous Cluster,” in Proceedings of the 2010 10th IEEE International Conference on Computer and Information Technology, ser. CIT ’10. Washington, DC, USA: IEEE Computer Society, 2010, pp. 1169–1174. [Online]. Available: http://dx.doi.org/10.1109/CIT.2010.212 276
[52] S. Romero, M. A. Trenas, E. Gutierrez, and E. L. Zapata, “Locality-improved FFT implementation on a graphics processor,” in Proceedings of the 7th WSEAS International Conference on Signal Processing, Computational Geometry & Artificial Vision, ser. ISCGAV’07. Stevens Point, Wisconsin, USA: World Scientific and Engineering Academy and Society (WSEAS), 2007, pp. 58–63. [Online]. Available: http://dl.acm.org/citation.cfm?id=1364592.1364602 276
[53] Y. Su and Z. Xu, “Parallel implementation of wavelet-based image denoising on programmable PC-grade graphics hardware,” Signal Process., vol. 90, no. 8, pp. 2396–2411, 2010. [Online]. Available: http://dx.doi.org/10.1016/j.sigpro.2009.06.019 276
[54] J. Lobeiras, M. Amor, and R. Doallo, “FFT Implementation on a Streaming Architecture,” in Proceedings of the 2011 19th International Euromicro Conference on Parallel, Distributed and Network-Based Processing, ser. PDP ’11. Washington, DC, USA: IEEE Computer Society, 2011, pp. 119–126. [Online]. Available: http://dx.doi.org/10.1109/PDP.2011.31 276
[55] P. Micikevicius, “3D Finite Difference Computation on GPUs using CUDA 2701 San Tomas Expressway,” Cell, pp. 0–5, 2009. 277
[56] L. Jacquin, V. Roca, J.-L. Roch, and M. Al Ali, “Parallel arithmetic encryption for high-bandwidth communications on multicore/GPGPU platforms,” in Proceedings of the 4th International Workshop on Parallel and Symbolic Computation, ser. PASCO ’10. New York, NY, USA: ACM, 2010, pp. 73–79. [Online]. Available: http://doi.acm.org/10.1145/1837210.1837223 277
[57] S. Hudli, S. Hudli, R. Hudli, Y. Subramanian, and T. S. Mohan, “GPGPUbased parallel computation: application to molecular dynamics problems,” in Proceedings of the Fourth Annual ACM Bangalore Conference, ser. COMPUTE
’11. New York, NY, USA: ACM, 2011, pp. 10:1—-10:8. [Online]. Available: http://doi.acm.org/10.1145/1980422.1980432 277
[58] NVIDIA, “DirectCompute para NVIDIA.” [Online]. Available: http://developer.nvidia.com/directcompute 277
[59] R. Andraka, “A survey of CORDIC algorithms for FPGA based computers,” in Proceedings of the 1998 ACM/SIGDA sixth international symposium on Field programmable gate arrays, ser. FPGA ’98. New York, NY, USA: ACM, 1998,
pp. 191–200. [Online]. Available: http://doi.acm.org/10.1145/275107.275139 278
[60] C. He, W. Zhao, and M. Lu, “Time Domain Numerical Simulation for Transient Waves on Reconfigurable Coprocessor Platform,” in Proceedings of the 13th Annual IEEE Symposium on Field-Programmable Custom Computing Machines. IEEE Computer Society, 2005, pp. 127–136. 279
[61] O. Pell and R. G. Clapp, “Accelerating subsurface offset gathers for 3D seismic applications using FPGAs,” SEG Technical Program Expanded Abstracts, vol. 26, no. 1, pp. 2383–2387, 2007. 280, 281
[62] Maxeler Technologies, “Maxeler: Complete Acceleration Solutions.” [Online]. Available: http://www.maxeler.com/content/solutions/ 280
[63] H. Fu, W. Osborne, R. G. Clapp, and O. Pell, “Accelerating Seismic Computations on FPGAs From the Perspective of Number Representations,” 70th EAGE Conference & Exhibition, no. June 2008, pp. 9–12, 2008. 280
[64] D.-U. Lee, A. Abdul Gaffar, O. Mencer, and W. Luk, “Optimizing Hardware Function Evaluation,” IEEE Trans. Comput., vol. 54, no. 12, pp. 1520–1531, 2005. [Online]. Available: http://dl.acm.org/citation.cfm?id=1098521.1098595 281
[65] D. Haugen, “Seismic Data Compression and GPU Memory Latency,” Master Thesis, Norwegian University of Science and Technology, 2009. 282
[66] T. Rø sten, T. A. Ramstad, and L. Amundsen, “Optimization of sub-band coding method for seismic data compression,” Geophysical Prospecting, vol. 52, no. 5, pp. 359–378, 2004. [Online]. Available: http://dx.doi.org/10.1111/j.1365-2478.2004.00422.x 282
Article Sidebar
Article Details
Carlos Fajardo, Universidad Industrial de Santander
Ph.D(c)Javier Castillo Villar, Universidad Rey Juan Carlos
Doctor en Ingeniería InformáticaCésar Pedraza, Universidad Santo Tomás
Doctor en Ingeniería InformáticaLos autores que publican en esta revista están de acuerdo con los siguientes términos:
- Los autores conservan los derechos de autor y garantizan a la revista el derecho de ser la primera publicación del trabajo al igual que licenciado bajo una Creative Commons Attribution License que permite a otros compartir el trabajo con un reconocimiento de la autoría del trabajo y la publicación inicial en esta revista.
- Los autores pueden establecer por separado acuerdos adicionales para la distribución no exclusiva de la versión de la obra publicada en la revista (por ejemplo, situarlo en un repositorio institucional o publicarlo en un libro), con un reconocimiento de su publicación inicial en esta revista.
- Se permite y se anima a los autores a difundir sus trabajos electrónicamente (por ejemplo, en repositorios institucionales o en su propio sitio web) antes y durante el proceso de envío, ya que puede dar lugar a intercambios productivos, así como a una citación más temprana y mayor de los trabajos publicados (Véase The Effect of Open Access) (en inglés).