
Leave-one-out Evaluation of the Nearest Feature Line and the Rectified Nearest Feature Line Segment Classifiers Using Multi-core Architectures
Main Article Content
Keywords
Multi-core computing, classification algorithms, leave-oneout test
Abstract
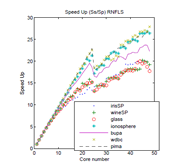
In this paper we present the parallelization of the leave-one-out test: a reproducible test that is, in general, computationally expensive. Parallelization was implemented on multi-core multi-threaded architectures, using the Flynn Single Instruction Multiple Data taxonomy. This technique was used for the preprocessing and processing stages of two classification algorithms that are oriented to enrich the representation in small sample cases: the nearest feature line (NFL) algorithm and the rectified nearest feature line segment (RNFLS) algorithm. Results show an acceleration of up to 18.17 times with the smallest dataset and 29.91 times with the largest one, using the most costly algorithm (RNFLS) whose complexity is O(n4). The paper also shows the pseudo-codes of the serial and parallel algorithms using, in the latter case, a notation that describes the way the parallelization was carried out as a function of the threads.
Downloads
References
[2] R. P. W. Duin, M. Bicego, M. Orozco-Alzate, S.-W. Kim, andM. Loog, “Metric Learning in Dissimilarity Space for Improved NearestNeighbor Performance,” inStructural, Syntactic and Statistical PatternRecognition: Proceedings of the Joint IAPR International Workshop,S+SSPR 2014, ser. Lecture Notes in Computer Science, P. Fränti,G. Brown, M. Loog, F. Escolano, and M. Pelillo, Eds., vol. 8621,IAPR. Berlin Heidelberg: Springer, 2014, pp. 183–192. [Online]. Available:https://doi.org/10.1007/978-3-662-44415-3{_}19 77
[3] S. Z. Li and J. Lu, “Face Recognition Using the Nearest Feature LineMethod,”IEEE Transactions on Neural Networks, vol. 10, no. 2, pp. 439–443,1999. 77, 79
[4] H. Du and Y. Q. Chen, “Rectified nearest feature line segment for patternclassification,”Pattern Recognition, vol. 40, no. 5, pp. 1486–1497, 2007.[Online]. Available: https://doi.org/10.1016/j.patcog.2006.10.021 77, 82
[5] J. Gama, I. Žliobait ̇e, A. Bifet, M. Pechenizkiy, and A. Bouchachia, “A Sur-vey on Concept Drift Adaptation,”ACM Computing Surveys, vol. 46, no. 4,pp. 44:1—-44:37, mar 2014. 77
[6] M. Bramer,Principles of Data Mining, 2nd ed., ser. Undergraduate Topicsin Computer Science. London, UK: Springer, 2013. 77
[7] B. Clarke, E. Fokoué, and H. H. Zhang,Principles and Theory for DataMining and Machine Learning, ser. Springer Series in Statistics. New York,NY: Springer New York, 2009. 78
[8] N. Lopes and B. Ribeiro,Machine Learning for Adaptive Many-Core Ma-chines - A Practical Approach, ser. Studies in Big Data. Cham, Switzerland:Springer International Publishing, 2015, vol. 7. 78
[9] A. Ahmadzadeh, R. Mirzaei, H. Madani, M. Shobeiri, M. Sadeghi, M. Gavahi,K. Jafari, M. M. Aznaveh, and S. Gorgin, “Cost-efficient implementationof k-NN algorithm on multi-core processors,” inTwelfth ACM/IEEE Inter-national Conference on Formal Methods and Models for Codesign, MEM-OCODE 2014, oct 2014, pp. 205–208. 78
[10] V. D. Katkar and S. V. Kulkarni, “A novel parallel implementationof Naive Bayesian classifier for Big Data,” inInternational Conferenceon Green Computing, Communication and Conservation of Energy, ICGCE 2013. IEEE, 2013, pp. 847–852. [Online]. Available: https://doi.org/10.1109/ICGCE.2013.6823552 78
[11] Y. You, H. Fu, S. L. Song, A. Randles, D. Kerbyson, A. Marquez,G. Yang, and A. Hoisie, “Scaling Support Vector Machines on modern HPCplatforms,”Journal of Parallel and Distributed Computing, vol. 76, pp.16–31, 2015. [Online]. Available: https://doi.org/10.1016/j.jpdc.2014.09.00578
[12] A.-L. Uribe-Hurtado and M. Orozco-Alzate, “Acceleration of Dissimilarity-Based Classification Algorithms Using Multi-core Computation,” inTrendsin Cyber-Physical Multi-Agent Systems. The PAAMS Collection - 15th In-ternational Conference, PAAMS 2017, ser. Advances in Intelligent Systemsand Computing, A. T. Campbell, F. de la Prieta, Z. Vale, L. Antunes, M. N Moreno, V. Julian, T. Pinto, and A. J. R. Neves, Eds., vol. 619, IEEE SystemsMan and Cybernetics Society Spain Section Chapter. Cham, Switzerland:Springer, jun 2017, pp. 231–233. 78
[13] E. Pekalska and R. P. W. Duin, “Dissimilarity representations allow forbuilding good classifiers,”Pattern Recognition Letters, vol. 23, no. 8, pp.943–956, 2002. [Online]. Available: https://doi.org/10.1016/S0167-8655(02)00024-7 79
[14] H. Che and M. Nguyen, “Amdahl’s law for multithreaded multicoreprocessors,”Journal of Parallel and Distributed Computing, vol. 74, no. 10,pp. 3056–3069, 2014. [Online]. Available: https://doi.org/10.1016/j.jpdc.2014.06.012 94
[15] J. Nutaro and B. Zeigler, “How to apply Amdahl’s law to multithreadedmulticore processors,”Journal of Parallel and Distributed Computing, vol.107, no. Supplement C, pp. 1–2, 2017. 94
Article Sidebar
Article Details
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License that allows others to share the work with an acknowledgement of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgement of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See The Effect of Open Access).